SEMM Programming Course
Matteo Cereda, Fabio Iannelli, and Uberto Pozzoli
Contact Us
| Who | At | |
|---|---|---|
Matteo Cereda |
matteo.cereda1@unimi.it |  |
Fabio Iannelli |
fabio.iannelli@ifom.eu |  |
Uberto Pozzoli |
uberto.pozzoli@lanostrafamiglia.it |  |
For any question, ideas, and comment reach us at these addresses
|
|
|
The Audience
Tipically this class is heterogenoues in terms of background and skills.
Introduction
“R for Data Science” will teach you how to treat data with R: You’ll learn how to get your data into R, get it into the most useful structure, transform it, visualise it and model it.

Cover image
What you will see
Data science is a huge field, our model of the tools needed in a typical data science project looks something like this:
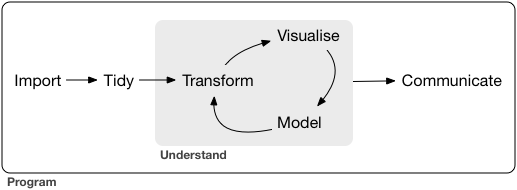
- First you must IMPORT your data into R. This typically means that you take data stored in a file, database, or web API, and load it into a data frame in R.
- Once you’ve imported your data, it is a good idea to TIDY it. Tidying your data means storing it in a consistent form that matches the semantics of the dataset with the way it is stored. Each column is a variable, and each row is an observation.
- Once you have tidy data, a common first step is to TRANSFORM it. Transformation includes narrowing in on observations of interest, creating new variables that are functions of existing variables, and calculating a set of summary statistics.
- Once you have tidy data with the variables you need, there are two main engines of knowledge generation: VISUALIZATION and MODELLING
- The last step of data science is COMMUNICATION.
The Goals
- Rules are the basics

Carl Lewis
- Data require dedication and precision

Patrick De Gayardon
- Performance can be improve when the brain is ON

To whitewash a large wall you don't need a big brush but a great brush
- Communication of results is half of the job
- Statistics is part of the other half but we were strongly advised not to teach it in this course…and WE have faithfully followed the orders

Please don’t
- CBs and MOs socialize with each other and share skills and ideas.
- MOs do not consider CBs as your bioinformatic technician and CBs don’t do the other way around

Ambrogio
A work by Matteo Cereda and Fabio Iannelli